base64는 아스키 문자열만 표현가능한 통신수단에서 바이너리 데이터를 교환하기 위해 만들어진 인코딩이다. 아스키 문자열은 7비트이고, 데이터 통신은 8비트 단위로 이뤄지기 때문에 만들어질 당시, 각 장비마다 이를 다루는 방식이 달랐고, 효율을 위해 특정 비트를 제거하고 통신하는 장비들도 존재했다. 이런 플랫폼 의존적인 문제를 피해 데이터를 회손없이 바이너리 데이터를 전송하기 위해 base64가 만들어졌다.
Base64는 원본데이터에 비해 약 1.3334배 많아지는 인코딩이다. 이런 단점에도 불구하고 안정적으로 바이너리 데이터를 텍스트로 변환할 수 있고, 플랫폼간 호환성이 좋다는 장점이 있기 때문에 현재에도 여전히 많이 사용되고 있다. Base64라는 이름은 64개의 아스키 문자열을 이용하는 인코딩 방식에 유래한것이다. 64개의 문자열을 사용하는 이유는 플랫폼과 관계없이 화면에 표시 가능한 아스키 문자가 127개이므로, 아스키코드로 색인이 가능한 수는 64개이기 때문이다.
인코딩은 바이너리 데이터를 6비트 단위로 나눈뒤, 나눠진 각 자리수를 해당 비트에 대응하는 아스키로 치환하는 방식이다. 64진법에 따라 치환되는 아스키 배열은 다음과 같다.
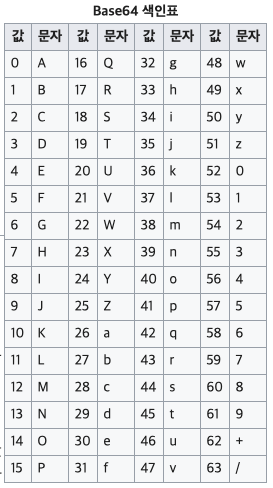
예를들어 abc를 utf8 binary bit로 변환하면 01100001 01100010 01100011 가 된다. 이를 다시 6비트씩 쪼갠뒤 10진수로 변환하면 24,22,9,35가 되고, 이를 색인표에 따라 아스키문자로 변환하면 최종 인코딩 값인 YWJj가 된다.
toBinaryString("abc") = "01100001 01100010 01100011"
011000 -> 24 -> Y
010110 -> 22 -> W
001001 -> 9 -> J
100011 -> 35 -> j
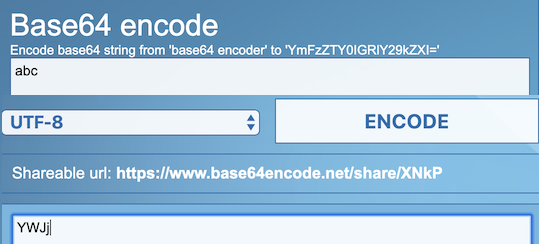
이는 https://www.base64encode.net/ 사이트에서 간단히 테스트 해볼수 있다.
위 예시와 다르게 6비트로 나눠떨어지지 않는 경우는 어떻게 인코딩될까? 이 경우에는 24비트 단위로 패딩을 추가해 인코딩한다. 패딩에는 인코딩 표에 없는 문자인 ‘=’을 사용한다. 먼저 0으로 채워 표현가능한 비트는 변환표를 거쳐 문자로 변환한다. 그리고 24비트중 패딩으로 채워진 나머지 부분은 =로 변환한다. 예를들어 a를 인코딩하는 경우는 다음과 같다.
toBinaryString("a") = "01100001"
011000 -> 24 -> Y
01+0000 -> 16 -> Q
padding -> NaN -> =
padding -> NaN -> =
참고자료
https://en.wikipedia.org/wiki/Base64
https://stackoverflow.com/questions/3538021/why-do-we-use-base64
http://blog.kevinalbs.com/base122